
美国学者称:许锦波本应共享2024诺贝尔化学奖
来源:网络 2024-10-22 10:56
塞拉菲姆·巴特佐格鲁(Serafim Batzoglou)觉得,许锦波应该共享2024年的诺贝尔化学奖。
他转发了诺贝尔化学奖的贴文并评价说,“并不是要否定哈萨比斯、朱默帕和贝克的贡献,但还有一个人本应得到诺贝尔奖的认可,那个人就是许锦波。他第一个开发出(精准预测蛋白结构)的深度学习算法,这一算法后来被复现和增强到最初版本的AlphaFold中。他本应与哈萨比斯一起获得诺奖。”
推文截图
巴特佐格鲁是计算基因组学专家,国际计算生物学会会士,曾任斯坦福大学计算机教授。
同样认可许锦波贡献的另一个行内人,是全球蛋白质结构预测比赛(CASP)的创办者、马里兰大学教授约翰·莫尔特(John Moult)。莫尔特说,“DeepMind这项工作(AlphaFold)背后的概念和方法,并非凭空而来,关键技术是深度学习方法的应用。毫无疑问,DeepMind直接建立在许锦波的工作之上。”
CASP号称蛋白质结构预测的“奥林匹克赛”。后来获得诺奖的AlphaFold,就是在2018年的第十三届CASP比赛上初露头角。再往前推一届,在第十二届CASP比赛里脱颖而出的,正是许锦波的RaptorX-Contact算法。事实上,第十三届里排名靠前的团队,都用了类似许锦波的算法。
对许锦波来说,诺奖颁给AI预测蛋白质结构,只是一个开始。他现在专注的,是正在爆发的新领域——AI设计和优化蛋白质。
什么是蛋白质结构预测?
许锦波觉得,自己是个单线程的人。
电脑的CPU可以同时执行很多任务,但许锦波在一个时间段,只想一个问题。虽然是急性子,但面对难题时,他反而能沉下心来,花很多时间,翻来覆去地琢磨,把问题想深、想透——这又有点像他研究的AI,很多层神经网络联合起来,去捕捉数据里浮现出的复杂模式,最后出色地完成任务。
高中时,许锦波是全国高中数学联赛的江西赛区第一名。大学时,他去了中国科学技术大学的计算机系。博士阶段,他出国深造,求教于算法和现代信息论的顶级专家李明教授门下。
那是2001年,人类基因组计划正如火如荼。李明教授也正在思考与之相关的两个大问题:第一,当时测序技术还不够好,没法把一整个染色体直接从头测到尾,只能切成小碎片来测,计算机怎么才能快速把一大堆小片段正确拼成完整的基因组?第二,当时的计算机速度也比较慢,用常规方法来分析基因组,可能要花上好几年时间。怎么才能快速对比两个巨大的基因组,找出里面相似的同源基因,以及不同的变异之处?
当时的研究者、资金、注意力,都集中在DNA和基因组上。不过,许锦波和李明教授讨论后,却选了一个很难的博士课题——蛋白质的结构预测。
蛋白质结构预测,一个60年难题
选这个课题,有两个原因:第一,它很重要,研究界渴望知道这个问题的答案,且短时间内不可能被其他科研组彻底解决,非常适合作为博士课题。第二,它很困难,这是个被清晰定义的问题——已知蛋白质的序列,也就是氨基酸在一维上的排列顺序,要预测出整个蛋白质里面每个原子的三维坐标。这个问题横亘六十年,进展始终不大,许锦波好奇,自己能不能把这个问题的边界,向前推进一点点。

许锦波演讲《AI预测蛋白质结构,但这只是一个开始》丨我是科学家
蛋白质是什么?它是细胞中最丰富的生物大分子。生物学的中心法则是,遗传信息从DNA流向RNA,又从RNA流向蛋白质。
假如把一个生物体想象成一家工厂,那么DNA就是最原始的设计蓝图;RNA是根据设计蓝图复写而来的很多本操作手册,每本手册里包含了制造某个特定产品的具体步骤;而蛋白质则是一个个最终的产品,是工厂的梁柱、门窗以及千形万状的结构,是工厂里自动执行各种功能的“分子机器”。
有些蛋白质是结构性的,有些蛋白质是功能性的。结构性的蛋白质组成生物的身体——头发和指甲里的角蛋白,皮肤里的胶原蛋白,肌肉纤维里的肌球蛋白,血管里的弹性蛋白。功能性的蛋白质推动生物体内的机能与反应——帮助消化吸收的淀粉酶、脂肪酶,控制血糖的胰岛素,运输氧气的血红蛋白,存储铁的铁蛋白,传递信号的神经递质……
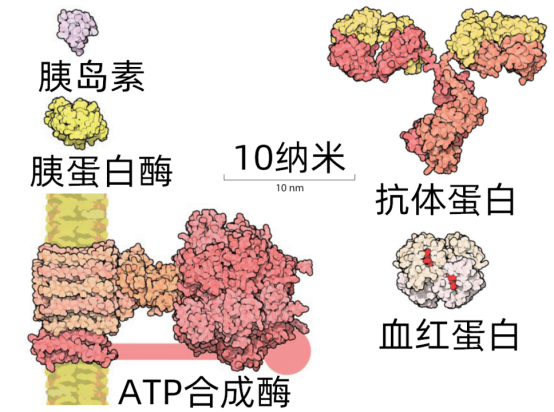
一些蛋白质的大小对比 。蛋白质分子的直径经常也就几纳米或者几十纳米,胰岛素只有51个氨基酸;助消化的胰蛋白酶有281个氨基酸;运氧气的血红蛋白有574个氨基酸;再大一点的有免疫系统用来对抗细菌病毒的抗体蛋白(1316个氨基酸),以及线粒体里提供能量的ATP合成酶(1125个氨基酸)。
蛋白质是由氨基酸构成的。想象一下,你有20种不同形状和颜色的柔性积木,每种积木可以无限量供应,那就是生物合成蛋白质所普遍使用的20种氨基酸。你能用这些积木搭出的不同形状,就相当于蛋白质的不同结构。
什么是蛋白质结构预测?简单点说,就是已经知道蛋白质用了哪些“氨基酸积木”,知道这些积木谁和谁接在了一起,这些积木在相连后依然可以进行一定的旋转和移动,那就是蛋白质里氨基酸残基的旋转自由度,要猜出最后拼搭出的形状。
所有可能的形状组合,是一个超出日常经验、以至于难以想象的天文数字。
举个例子,假如只是一个用了100块积木的模型,每个积木和其他积木相连时只有2种不同的拼法,那么所有可能的形状组合,就是2的100次方,也就是1.27×1030种。
这个数字有多大呢?假设有台超级计算机,每秒能算1亿种不同的形状。它把这2100种形状算一遍,需要4 ×1014年——宇宙诞生至今也就138亿年,这个时间足够宇宙反复诞生29128次。
问题很难,但单线程的许锦波依然决定走上蛋白质结构预测这条单行道。这条路,他一走就是24年。
RaptorX算法诞生,启发AlphaFold
最开始,许锦波想的是改进当时的主流方法——“能量优化”法。
一颗球放在山顶上,轻轻一碰,就会滚到山脚,这就是自然地从“能量高的状态”转变为“能量低的状态”。
对于蛋白质分子来说,科学家也猜测里面的所有原子会自然地找到能量最低的稳定状态,那就是蛋白质最后折叠出的结构。
“能量优化”法就是这个原理。但“能量优化”的问题在于,预测比较小的分子时还好,但分子越大越复杂,得出的结果就会越差。
蛋白质平均会用到几百个氨基酸,由几千几万个原子组成,结构的可能性迅速增长到天文数字,找出“最优能量”几乎是个不可能的任务。事实也证明,与结构生物学家做实验解出的结构相比,“能量优化法”预测出的结构始终误差较大。
机器学习与深度学习登场
从2006年开始,许锦波逐步转向新兴的机器学习和深度学习方法。

如果说“能量优化”还大量依赖于人去手把手指导计算机,那么机器学习和深度学习就开始鼓励计算机“自学”了,当然,这种“自学”仍然需要人类的算法和策略指导。计算机分析已知的蛋白质序列和结构,自己去发现其中蕴藏的规律,然后据此再去预测一个未知蛋白的结构。
相比“能量优化”,“机器学习”和“深度学习”无疑是一种颠覆。就像人的大脑可以在极端复杂的环境里磨炼自己的直觉和反应,计算机也可以通过训练来不断改进自己的能力,可以处理混乱的、残缺的、不完美的信息。
唯一的问题是,结果还是不够好,预测出的结构,误差还是比较大。和老方法相比,提升几乎可以忽略不计。
能试的路似乎都已经走到了尽头。很多人开始离开蛋白质结构预测的这个领域,研究基金越来越少,参加CASP比赛的队伍也越来越少。许锦波回忆说,“在2006年到2016年这10年间,大家都觉得这个问题没办法做出来,很多人都离开这个领域去做其他的问题了。
对许锦波来说,突破是在2016年到来的。
决定性突破:利用蛋白质的全局信息
那个思考良久的问题,在大脑的层层神经回路里来回碰撞、循环、激发,有一天,一个灵感忽然浮现。
“关键就是一点,要尽可能地用上蛋白质的全局信息”,许锦波说,“之前的深度学习还是在使用局部信息去预测。”
拿一个由300个氨基酸组成的蛋白质来说,以前的预测方法每次只关注某几个位置的氨基酸信息,比如第一个氨基酸、第十个氨基酸 或者第一百个氨基酸;也可能只关注某一个局部区域,比如第20个到第30个氨基酸……总之,关注的都是一些局部信息。
许锦波的想法是,一定要让AI把从第1到第300个氨基酸的全局信息全用上,当然,难点就在怎么收集这些全局信息,“我尽可能用比较深的神经网络去做,也是因为多层的网络更能抓取到蛋白质的全局信息,它是一个合适的工具。”
就像在玩一个难度极高的拼图游戏,许锦波耐心地训练AI寻找线索:要看有哪些小碎片特别契合、经常一起出现(氨基酸的共进化);要对比分析,看哪些小碎片是从其他拼图里继承来的(保守序列);要预测哪几块小碎片会互相接触(氨基酸的接触预测),任意两块碎片之间的距离是多长(氨基酸的相互作用强度);最后把所有信息汇总成数学上的矩阵,又把矩阵转换为图像,然后让AI用识别图像的方式去识别“蛋白质全局信息图”
许锦波拿这个方法去预测了一个200多个氨基酸的膜蛋白结构,发现误差只有2.29个埃,大概0.2纳米,两个原子的宽度。
为什么选择膜蛋白?许锦波说,“目前的实验技术去解析膜蛋白结构是很困难的,所以数据库里就没有太多的膜蛋白结构。以前的算法也就没有足够的膜蛋白数据去用于训练,所以在预测膜蛋白结构时往往会失效。但我的RaptorX算法在不需要用膜蛋白数据去训练的情况下,还可以把膜蛋白的结构预测得相当好。这就意味着RaptorX算法不是依靠简单地记住训练数据,不是单纯依赖相似的序列而推导出相似的结构。而是它抓取全局信息后真正学到了一些底层的规律,于是有了比较好的预测能力。”
那一刻,许锦波知道,这方法成了。

许锦波在芝加哥大学丰田技术研究所任教时,与芝加哥大学的师生多有交流合作。
新思路,启发2024诺贝尔奖得主
2016年秋天,许锦波在芝加哥参加了一个小型报告会,和同行分享了自己的进展。参加这个会议的人里,一个正在芝加哥大学生物物理系读博的娃娃脸年轻人听完报告,还和许锦波的学生交流了不少。
那个年轻人就是不久前刚刚获得诺贝尔化学奖的约翰·朱默帕(John Jumper),几个月后,他从芝加哥大学博士毕业,加入Google的Deepmind团队——2016年3月,那个团队做出的AlphaGo刚刚以4:1打败了人类的冠军棋手李世石,再过几年,这个团队将带着AlphaFold再度出山。
2017年,许锦波将这个方法写成论文《通过超深度学习模型精确预测蛋白质接触图》[1],发表在国际计算生物学的旗舰期刊PLoS Computational Biology上。这篇论文在2018年被这个期刊评为创新突破奖,至今被引用了1200多次。
诺奖得主哈萨比斯、朱默帕后来发表的关于AlphaFold的论文《基于深度学习的改进的蛋白质结构预测》《使用AlphaFold进行的精准蛋白质结构预测》,以及朱默帕的博士论文,都引用了许锦波的多篇论文。
CASP创办者莫尔特教授说,在早期,CASP竞赛的大多数参赛算法只能称之为“随机”,大多数结构预测都是“看上去就令人痛苦的物体”。那时候,竞赛地点定在一个有着木地板的古老教堂里,如果上去讲自己算法的人讲得太乱或者吹嘘太过,底下的听众就会在木地板上“友好地跺脚”,整个空间里仿佛回荡着巨大的鼓声。
许锦波没有收到“友好的跺脚”,相反,他的算法带来了突破。莫尔特曾经统计过,从CASP竞赛创办以来,对于最困难的蛋白质结构预测任务,参赛算法得分一直徘徊在30分左右,但后来出现了两次飞跃。第一次飞跃就是许锦波的RaptorX,作为第一代AI算法,把预测分从30分拔高到了60分。第二次是AlphaFold2,作为第二代AI算法,把预测分又拉到了80多分。
资源紧缺
算法和模型上取得了突破,但许锦波要再进一步提升预测的精度时,发现瓶颈卡在了资源上。
2014年刚开始尝试深度学习方法时,许锦波甚至没有GPU,都是用CPU去训练的,构建不了太多层的神经网络。到了16年,他终于有了12G显存的GPU,能构建出60层的神经网络,但依然没法加太多参数,否则就会因为内存不够用而没法训练。后来他靠申请来的研究基金一张张攒卡,一台机器安4张GPU卡,是他最好的配置。
除了算力,人手也很紧缺,许锦波自己一行行写代码,带的团队一般就在2~3人,即使加上合作者,也从来没超过5个人。
相比之下,做出AlphaFold的Deepmind团队,背靠谷歌,算力和人才都充裕得多。2020年附近,AlphaFold团队就已经拉起了30人的队伍,里面有许多专门的AI算法优化工程师,可以用上几百块GPU,去实现极耗算力的注意力机制网络。
对于蛋白质预测,对于深度学习的AI大模型,学术界的资源和进度,越来越落后于有着“钞能力”和强大算力支撑的工业界。足够好的工程加上足够多的资源,堆出来的量变足以引发质变。
许锦波已经在学术界证明了自己,他发表的论文已经被引用了一万多次,当选为计算生物学会的会士,曾获美国斯隆研究奖、前沿科学奖、美国自然科学基金早期职业奖、《PLoS Computational Biology》创新突破奖、国际计算生物学顶级会议 RECOMB 最佳论文奖和时间检验奖等等。
这一次,他想在工程上做得更好更彻底,做出实在的东西,解决真实的工业界问题。
他选择回国创业。
捧出一颗分子之心
回到国内,2022年,许锦波创立了名为“分子之心”(MoleculeMind)的公司,组起一支“五花八门”的强大团队,有做生物的、做计算机的、做药物和临床的各路学霸专家,整个团队里80%是研发,研发团队里90%是博士。
AI设计出的分子,不能仅仅在虚拟环境里跑出一个高分,而是最终要到现实里去经受生物实验和工业生产的考验。许锦波希望团队里的人不仅要有很强的技术背景,而且学习能力强,和其他不同背景的人也能很好地交流,“我们在做的事情是交叉学科里比较大的项目,而且是从零到一,很多项目此前没有别人做过。这就需要团队在一起密切合作。如果团队之间不能互相理解、顺畅交流的话,效率就会非常低了,有些事情甚至做不出来了。通常来说,我们很多解决方案都是既需要懂计算、懂AI,也需要懂生物背景。很多事情还需要大家边做边学。”
一位分子之心的团队成员说,在他们团队里日常的消遣是做数学题,最难的那种,题目丢进群,一会儿,学霸们纷纷把解题思路和答案发出来,许教授也会参与。
“ 中午吃完饭,晚上休息时,大家在一起闲着就会做点题,数学题比较多,有时候也会搞点物理题、人文题、历史题,”许锦波说,“我们这里学霸多,喜欢互相挑战。”
拉起这支精兵强将,许锦波并不打算重做一个AlphaFold,他的野心更大一些......
让AI“按需设计”蛋白质
自然里存在的蛋白质不是天上掉下来的,它们必须满足种种条件,比如要始终适应变化的环境,一次适应不了,它所归属的生物就灭绝了。它们有来处、有源头,是在漫长的演化过程里逐渐形成的。而演化有路径依赖,演化喜欢重新利用已有的东西,缝缝补补,略加改动,将就着用。
而AI没有历史包袱,AI可以设计出自然界里从未存在过的全新蛋白质。
人体里可能有十万种蛋白质,现实里能找到的蛋白质可能有几十亿种,看上去很多,但光是一个300个氨基酸的蛋白质理论上就有20300种可能。
如果说理论上可以存在的蛋白质就好比地球上的海洋,那么大自然迄今制造出的蛋白质,不过是海洋里的一滴水。
但AI设计出的蛋白,能比大自然设计出的更好吗?许锦波需要一个“里程碑”,来证明这件事行得通。
证明来得很快,就在分子之心创立一年多的时候。
佳绩频出
那时候,许锦波这个单线程的科学家,正逐渐适应了多线程的创业,他一边组建团队,一边继续开发算法训练AI,一边引入投资方和合作方。
当时,中国的合成生物学的一家龙头企业找到了分子之心。这家公司遇到的问题是,一个蛋白的优化陷入了瓶颈。
那是合成步骤里的一个关键催化酶,极具商业价值又涉及行业瓶颈,它是一个跨膜蛋白,用传统的实验方法优化了十几年,现在已经到达了优化极限。使用生物方法解析晶体结构需要耗时数月甚至数年,且成功率极低。该酶参与的反应过程异常复杂,需要多步反应,涉及辅酶、电子传递等复杂因素。这导致很难用传统的定向进化方法,借助高通量实验来对这个酶进行优化。
用其他AI来优化也依然很难,酶的催化反应是一个动态反应的过程,酶的催化反应是一个动态反应的过程,AlphaFold2等工具的功能局限于蛋白质静态结构预测,也不能产生新的蛋白质序列,与真实的需求差异较大,难以满足精准的蛋白质设计的需求
要精准优化,需要具备预测蛋白质动态结构的能力。
这项优化工作原定2~3年内完成,但分子之心综合运用AI蛋白质技术和量子化学、分子动力学等科学计算方法,实现了蛋白质动态设计,只花了6个月,就设计出了一个活性和特异性更高的新酶。
产业方实验数据显示,相对于野生菌,AI设计的这个酶使菌种产率提高了5倍!

AI设计和优化的蛋白,有时候的确会走出奇妙的“神之一手”。
有一回,许锦波团队要优化另一个酶,做传统实验的科学家建议改动酶的几个功能区域,毕竟那里是酶去结合底物、催化反应的地方。然而,AI却建议改一个距离功能区很遥远的氨基酸。
“怎么改这个地方呢?”传统派科学家觉得太扯了。然而,真的根据AI建议改动后,实验却得出了不错的结果。
后来发现,这个酶在反应时,会把远处的这个氨基酸给折叠过来,凑到功能区附近,等反应结束,这个折叠又打开,那个氨基酸就又归位到距离功能区很遥远的地方。
有些改动在没看到AI给出的结果之前,人根本就想不到。但一旦看到AI改动后的结果,再多琢磨一下,就会觉得AI有它的道理。就像不走定式的AlphaGo,在对弈中下出了不少人类棋手不会有的开局和棋步,有些在人类棋手看来甚至像是“恶手”,但最终证明是对全局有利的。
为什么AI能做出传统实验做不到的优化?可能是因为AI一开始挑选的余地,就远远大于传统的实验方式。如果说传统实验方法的“搜索空间”是在几十万种可能性里搜索,那么AI的“搜索空间”是从百亿种可能里去搜索。
而许锦波训练的AI算法,能将这百亿种可能,精准地缩减到几十种可能。在后续的实验验证步骤里,这几十种可能里,几乎总能涌现出不止一种满足需求的蛋白质分子:增强了一种塑料降解酶的活性,而且把这种酶在菌株里的产量提升了400%;改造了一种抗癌细胞因子,在保留了原本的抗肿瘤效果的同时,把它的毒副作用降低到了原本的千分之一;优化了一种代糖用酶,让这种酶的半衰期从2.3小时延长到了将近200小时,大幅降低了生产成本……
分子之心还在做一些尝试,比如优化发酵工艺,设计出一种特别的中间蛋白,把中间的三步反应变成一步反应,减少了中间环节,工艺的可控性会升高,产率也能升高,而且减少了对发酵罐、水电成本的需求,成本可以大幅下降。
有些生物合成公司已经卷到在建立自己的小型发电站,来节省电费成本。相比之下,优化生产环节,才是真正釜底抽薪的降本增效。
去年,随着大语言模型与生成式人工智能的兴起,不少科学家认为,基因与蛋白质序列,与语言序列存在相似性,大语言模型也同样可以应用在蛋白质上,Meta的AI科学家也做了这样的工作,并且把它发到了《Science》上。
分子之心也将其应用到蛋白质生成领域,推出了名为“NewOrigin”(达尔文)的蛋白质大模型。生物学家通过和“达尔文”进行对话,就能获得AI辅助设计的蛋白质。

NewOrigin,达尔文,这个名字的意思是,这将是一次AI驱动的新物种起源。蛋白质的进化,将从大自然的随机进化,变成AI设计的定向进化。
在一项与药企的合作中,达尔文大模型对野生型蛋白进行突变设计,优化蛋白的稳定性、表达量等多个目标,仅仅三天就设计出数十个理想的候选蛋白,动物实验显示,疫苗产生中和抗体滴度为已公开专利和相关大型药企蛋白疫苗的数倍。
如果说传统的实验方法是“大海捞针”,许锦波的AI方法就是先“百亿里挑几十”,然后在几十种分子里“优中选优”。
这不仅大幅降低了成本,也大大缩减了研发时间,传统方法要花几年、几个月,许锦波的AI方法只要花几星期、几天。
许锦波相信,这个时间还会再缩短——到几小时,甚至几分钟。
对AI和合成生物学来说,这可能是最好的时代。
中国2022年发布的《“十四五”生物经济发展规划》里,对生物技术与信息技术融合应用提出了明确的要求,以及建设关键共性生物技术创新平台等。
2023年,美国白宫科学技术政策办公室发布了一份更具体的报告,呼吁有关部门重视生物制造技术的潜力,以生物技术解决气候、粮食、供应链安全、健康等宏大问题,共21个方向、49个具体目标,其中包括要将AI应用于生物设计与生物工程,目标是在5年之内,实现精确地设计酶或者小分子,可以选择性结合任何所需的靶点,且设计蛋白质耗时不超过3个星期。
今年5月,AlphaFold 3推出,并由DeepMind子公司Isomorphic Labs开始推进商用,相关技术不再开源。在科研上,AlphaFold仍然是蛋白质预测的AI工具,而在商业上,他们的任务很明显:设计突破性药物。2024 年 1 月,Isomorphic Labs 宣布与礼来和诺华达成两项价值 30 亿美元的药物研发协议。这里的关键问题,还是对蛋白质结构、功能的理解,蛋白质与配体、蛋白质与蛋白质的相互作用等。
对比美国所要走的路线图,分子之心其实已经在快速解决其中的一些关键问题,比如分子之心做出的AI蛋白质优化设计平台MoleculeOS,其中融合了十几项全球领先的算法,可以进行蛋白质结构预测、蛋白质侧链结构预测与基于侧链信息的序列设计、抗体抗原复合物结构预测,抗体设计、酶稳定性优化、酶活性优化等工作。
“现在做这个方向的团队越来越多,但我对我们的算法有信心,比如在酶的设计改造上,我们团队肯定是世界领先的。我的长期目标是,别人要一个特定功能的蛋白质,我用我的AI,在电脑上操作几分钟,就可以设计出一个现实里符合要求的分子。”许锦波说,“我希望打造出中国生物经济时代的基础设施。”
参考文献:
Wang, S., Sun, S., Li, Z., Zhang, R. & Xu, J. Accurate de novo prediction of protein contact map by ultra-deep learning model. PLOS Comput. Biol. 13, e1005324 (2017).
Jinbo Xu. Distance-based protein folding powered by deep learning. PNAS, 2019
Xu, J., Mcpartlon, M., & Li, J. (2021). Improved protein structure prediction by deep learning irrespective of co-evolution information. Nat. Mach. Intell., 34368623. Retrieved from https://pubmed.ncbi.nlm.nih.gov/34368623
Jumper, J., Evans, R., Pritzel, A. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021). https://doi.org/10.1038/s41586-021-03819-2
《“十四五”生物经济发展规划》
https://www.ndrc.gov.cn/xxgk/zcfb/ghwb/202205/P020220510324220702505.pdf
美国白宫科学技术政策办公室报告
https://www.whitehouse.gov/wp-content/uploads/2023/03/Bold-Goals-for-U.S.-Biotechnology-and-Biomanufacturing-Harnessing-Research-and-Development-To-Further-Societal-Goals-FINAL.pdf
版权声明 本网站所有注明“来源:生物谷”或“来源:bioon”的文字、图片和音视频资料,版权均属于生物谷网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:生物谷”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
